Embodied Robot and Textual Interfaces for Sign Language Interpretation
🗺 Location: KTH Royal Institute of Technology, Stockholm, Sweden
📅 Duration: Autumn 2025
👩🏫 Guided by: Prof. Iolanda Leite

User study setup with the Furhat robot, ASL video display, participant position and camera input.
Objective Link to heading
To study how physical embodiment changes the way people experience automated sign language interpretation. We compared two ways of presenting the same interpreted content:
- A standard text display.
- A Furhat social robot that speaks the interpretation and uses gaze and head movement.
The project focused on the output modality of interpretation rather than building a new sign language recognition model. This allowed us to isolate whether embodiment, speech and social cues make the system feel more engaging, natural, trustworthy or partner-like.
System Design Link to heading
We built two paired subsystems, each with a robot version and a display version. The underlying logic was kept equivalent across modalities so that only the output channel changed.
Gesture-based Rock-Paper-Scissors Link to heading
The active interaction task was a Rock-Paper-Scissors game using a webcam and MediaPipe Hands. The camera pipeline extracted hand landmarks and classified gestures using deterministic finger-extension rules for rock, paper and scissors. A stability filter accepted a gesture only after consistent detections, reducing false triggers during real-time play.
In the robot condition, the Furhat robot greeted the participant, ran the game loop through speech, announced its move and reacted to the result. In the display condition, the same game state, prompts and results were shown through a fullscreen graphical interface.
ASL Interpretation Interface Link to heading
The interpretation task used a Wizard-of-Oz style setup with prerecorded ASL videos and fixed English translations. No autonomous ASL recognition was used in this study. Instead, the videos and translations were controlled so that both modalities presented the same information.
In the Furhat condition, the robot turned toward the ASL video, waited while the signer was shown, turned back to the participant and spoke the translated sentence. In the text condition, the translation was shown as large centered text after the same video sequence.
User Study Link to heading
We ran a within-subjects study with 26 participants. Each participant experienced both the robot and display conditions for the Rock-Paper-Scissors task and the ASL interpretation task. The order of modalities was counterbalanced.
Participants rated engagement, social presence, naturalness, trust and comprehension. We also collected comparative preferences and open-ended feedback after the tasks.
Results Link to heading
Active Interaction Link to heading
The robot made the game feel more engaging without changing the perceived quality of gesture recognition. Participants rated the robot higher for fun, attention, liveliness and naturalness, while competence and gesture-detection accuracy remained comparable to the display.
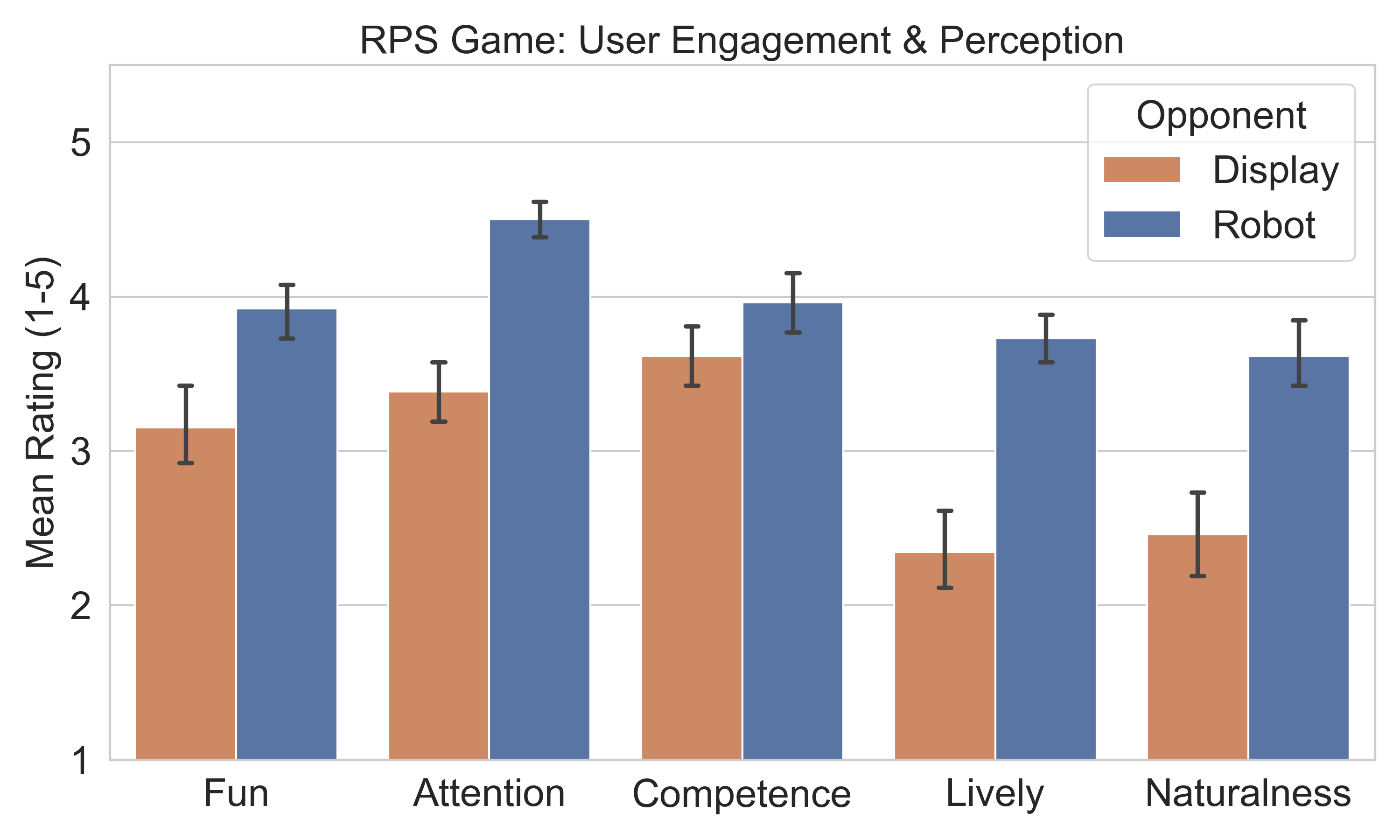
User ratings for the Rock-Paper-Scissors task.
ASL Interpretation Link to heading
For ASL interpretation, the robot was perceived as more sociable, emotional and partner-like than the text display. However, perceived trust was the same for both systems, and comprehension was similar. This suggests that the robot added social presence without improving or reducing the perceived reliability of the interpreted content.
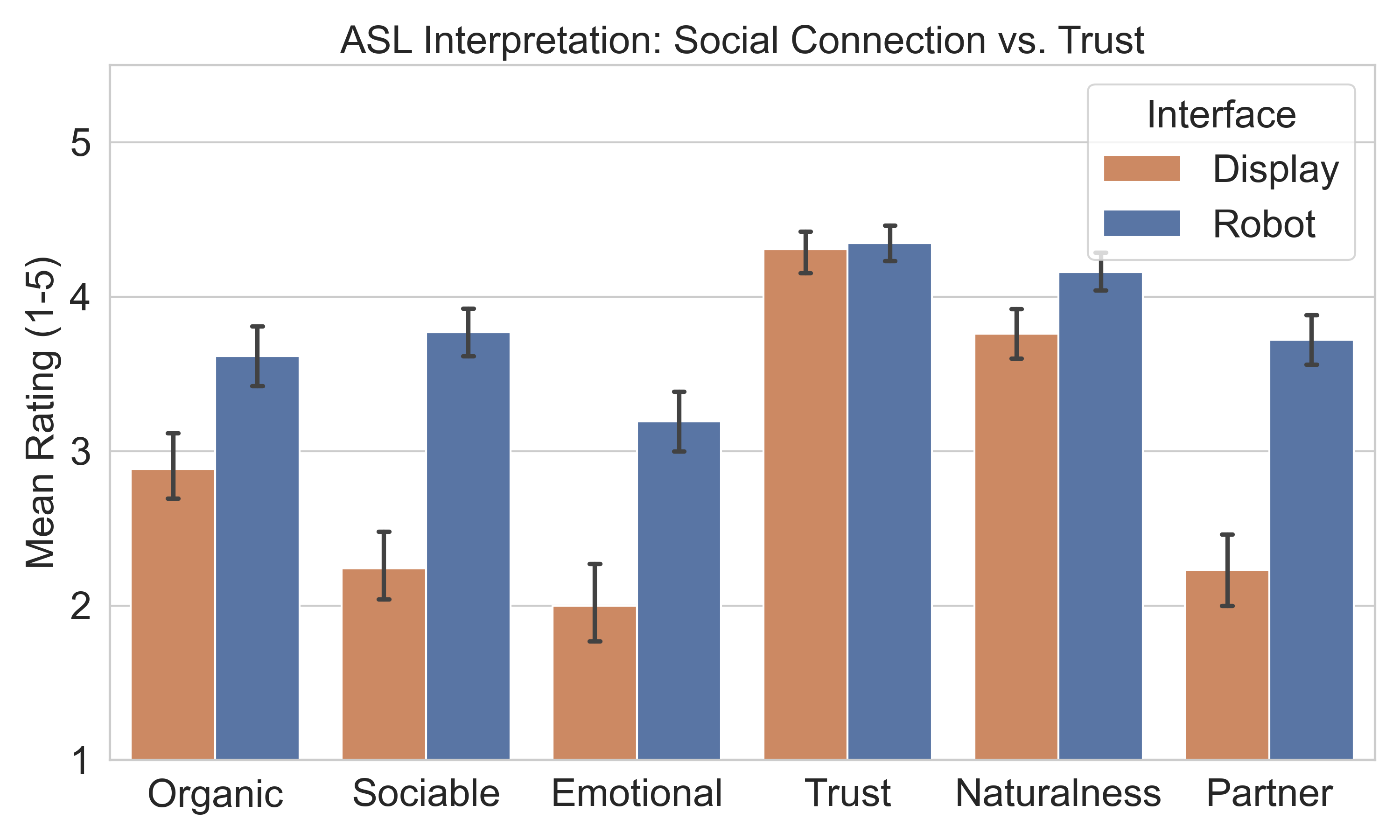
Social and functional ratings for the ASL interpretation task.
Preference Link to heading
Participants strongly preferred the robot for interaction: 87.5% preferred it for Rock-Paper-Scissors and 75% preferred it for ASL interpretation. When asked specifically about trustworthiness, preferences were split, with the text display slightly preferred.
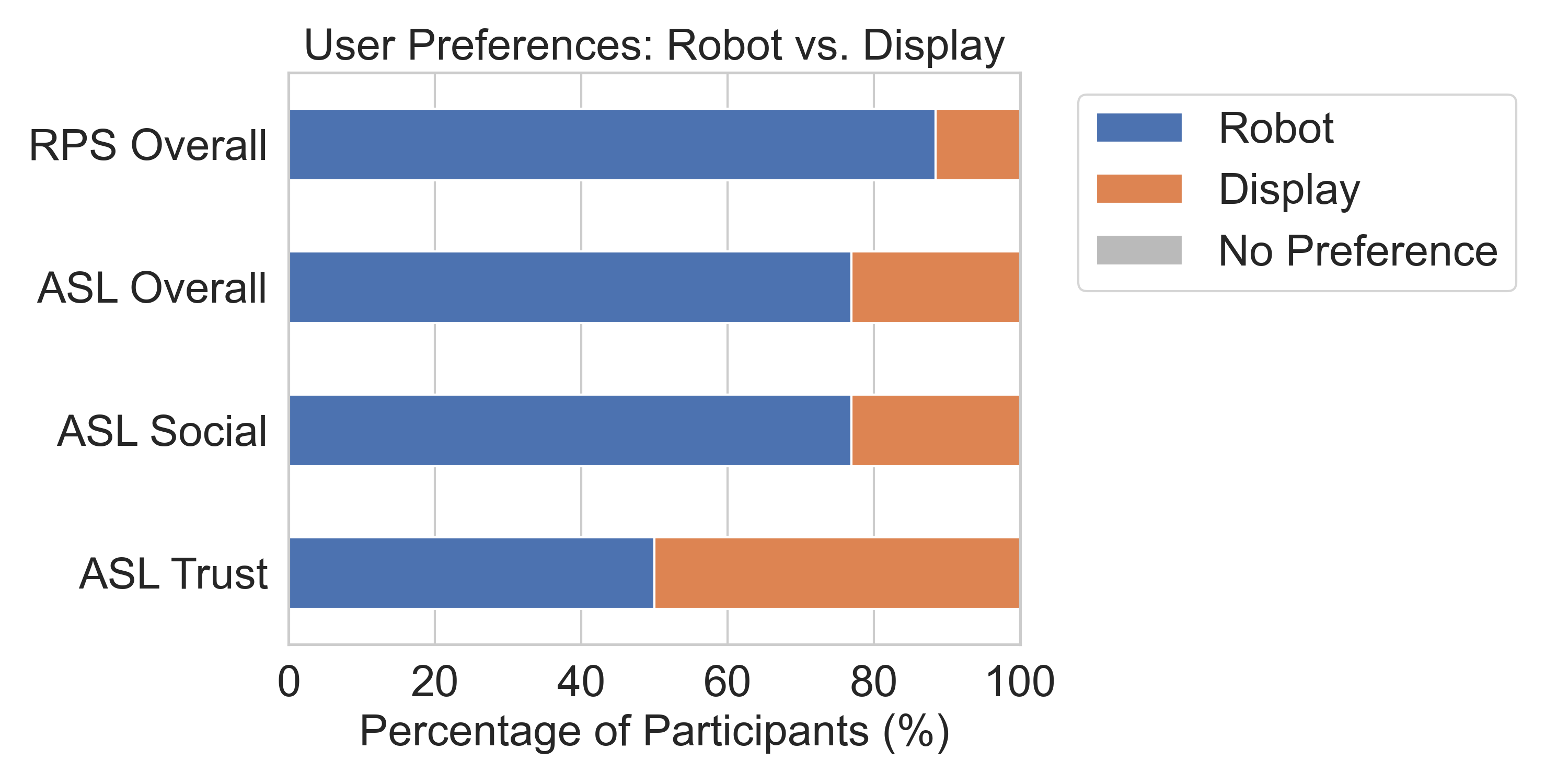
Overall participant preferences between the robot and display interfaces.
Design Takeaways Link to heading
The main finding was a clear split between functional trust and social preference. The Furhat robot did not make the interpretation more trusted than text, but it made the interaction feel more social and connected.
This suggests that embodied robot interpreters are useful in settings where social connection matters, such as education, service interactions or face-to-face assistance. For fast, high-stakes or purely administrative communication, a text display may still be more efficient.
The project also highlighted the importance of keeping a text fallback. Participants with more negative attitudes toward robots were less likely to prefer the robot in the active interaction task, so embodiment should be treated as a context-aware option rather than a universal replacement for text.